上一章節咱們學習到了,在並行情況下 mysql 可能會發生什麼樣的資料不一致問題,並且也學習到了這些問題它又是如何解決。
雖然 innodb 已經儘可能的解決上述這些問題,但是如果要完全解決,性能代價太大,因此後來有了一些折衷方案,這個東西就叫做 :
事務隔離級別
接下來本篇文章將要談談這東西,並且整理一下 innodb 預設的一些鎖的設定。
資料庫在並行運行時,通常會發生以下幾種問題,並且也探討過這幾種問題的解法 :
而在 innodb 事實上可以『 完全簡單 』的處理上面幾種現象,解決方法如下圖 5 所示,也就是同一個時間,只能執行同一個事務,如下圖所示。也就是把發生問題的根本原因『 並行 』給移除。
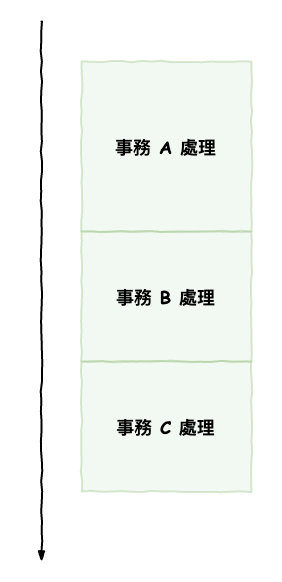
圖 1 : 一致性的根本解法
但這會嚴重的影響到效能的問題,因此才有了『 隔離層級 』這東西。
隔離層級可以讓你決定需要處理到什麼層級的一致性問題
也就是說上面四個問題,它可以讓你根據性能的要求,來決定你要處理幾個問題,處理的越多代表性能越差,處理越少個則代表性能越好,但反之不一致性機率更高。
mysql 總共提供以下四個層級,不過比較準確的說,這是所有資料庫共有的層級,性能從高至低排序,而反之資料一致性性由低至高。
它們可以解決的難題如下列表,其中有個地方要注意一下,那就是 RR 級別的幻影讀解決,在 innodb 只能算是部份解決,不能說完解,上一章節幻讀情境 3 就是無法解。
| 更新不一致 | 髒讀 | 不可重複讀 | 幻影讀 | |
|---|---|---|---|---|
| read uncommitted | v | x | x | x |
| read committed | v | v | x | x |
| repeatable read | v | v | v | v or ? |
| serializable | v | v | v | v |
~ 小知識 1 ~
在大部份的資料庫世界中,都有用這個事務隔離級別來處理以上幾個難題,但比較不同的在於 mysql 預設是使用 repeatable read ( RR ) 來當預設,而其它資料庫例如 orcale、ms sql server 是使用 read committed ( RC ) 來當預設。
會有這樣的差別在於,RC 級別所會碰到的『不可重複讀』問題事實上還算可以接受。因為它是讀到已經 commit 的資料。
~ 小知識 2 ~
你可以執行以下 sql 來看看你系統的隔離層級
SHOW VARIABLES LIKE '%transaction_isolation%';
~ 小知識 3 ~
你可以執行以下指令來修改隔離級別,但是你要很明確的知道,如果降低或增加級別可能會產生的風險。
SET SESSION TRANSACTION ISOLATION LEVEL {level};
Ex.
SET SESSION TRANSACTION ISOLATION LEVEL read committed;
innodb 基本上它的預設為 repeatable read (RR),咱們要在這裡總結一下,在這個級別的所有操作預設是會如何處理,如何的上鎖。
select 有三個重點要記得 :
其中解釋一下第二點,如下圖 2 所示,事務 b 的 select 操作都不會被卡住,原因在於有 mvcc 機制,它讀取時都會讀,事務開始前的最新一個版本。
那有人會問,事務 a 不是在 update 時會上鎖嗎 ? 那不是應該不能有人讀嗎 ? nono ~ 不是的
它上是有上鎖,它上的鎖是所謂的『 排它鎖 』,它不是指上了就不讓人讀,而是上了,別人無法在加鎖,而由於 select 本身不加任何鎖,所以 ok 可以讀。等等後面有這鎖更詳細的說明。
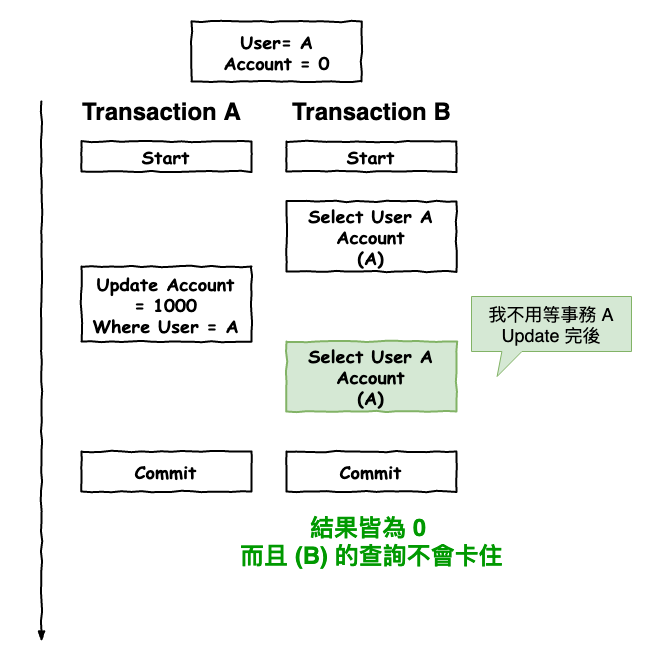
圖 2 : select 在 rr 級別不會卡
~ 小備註 1 ~
上述操作看起來和 select 沒啥關係,但實際上是會隱性的用到 select,例如上述當前讀操作的 update 或 delete 它們實際上會用 select 先去找找要修改的欄位在不在,而這時它用的就是『 當前讀 』,也就是直接取得最新版本。
~ 小備註 2 ~
關於上述提到的『 mvcc 』與『 當前讀 』什麼的可以連到前一篇文章來看看,傳送門如下。
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
上面是基本 select 的行為,它預設不上鎖。
但是 mysql 有提供兩種方法可以給我們手動在 select 上鎖。
其中要注意,它們兩個上的鎖是不同的。
共享鎖當執行以下範例時會被卡住 :
-- 範例 1 --
事務 A
(1) SELECT * FROM user WHERE age = 20 LOCK IN SHARE MODEL; ( 上共享鎖 )
事務 B
(2) UPDATE user SET name = 'mark' WHERE age = 20; ( 想加排它鎖,會失敗卡住 )
-- 範例 2 --
事務 A
(1) SELECT * FROM user WHERE age = 20 LOCK IN SHARE MODEL; ( 上共享鎖 )
事務 B
(2) SELECT * FROM user WHERE age = 20 FOR UPDATE; ( 想加排它鎖,會失敗卡住 )
而當上排它鎖時,以下幾個範例會被卡住。
-- 範例 1 --
事務 A
(1) SELECT * FROM user WHERE age = 20 FOR UPDATE ( 上排它鎖 );
事務 B
(2) UPDATE user SET name = 'mark' WHERE age = 20; ( 想加排它鎖,會失敗卡住 )
-- 範例 2 --
事務 A
(1) SELECT * FROM user WHERE age = 20 FOR UPDATE ( 上排它鎖 );
事務 B
(2) SELECT * FROM user WHERE age = 20 FOR UPDATE; ( 想加排它鎖,會失敗卡住 )
-- 範例 3 --
事務 A
(1) SELECT * FROM user WHERE age = 20 FOR UPDATE ( 上排它鎖) ;
事務 B
(2) SELECT * FROM user WHERE age = 20 LOCK IN SHARE MODEL; ( 想加共享鎖,會失敗卡住 )
根據上幾個範例可以整理出下述這張表,它的 ok 表示可以上鎖成功。
| 排它 | 共享 | |
|---|---|---|
| 排它 | 失敗 | 失敗 |
| 共享 | 失敗 | OK |
注意事項
最後手動加鎖有個注意事項,如果是查詢條件為範圍的如下範例,那它的鎖會變成範圍的,也就是會不會只鎖單行,而會鎖某個範圍的行數。( next-key locking 上篇有說 )。
SELECT * FROM user WHERE age > 20 FOR UPDATE;
上面有提到,如果有一段操作沒有命中索引,那它就會變成表鎖,例如下面範例 :
UPDATE user SET name = 'mark';
同時上面還是有提到,如果在進行 update 時會針對『 行 』上『 排它鎖 』,但是這種情況會變成將『 表 』上『 排它鎖 』。
但是這裡有一個問題,那就是如果這張表要上『 排它鎖 』,那前提就是這張表裡面『 不能有上排它鎖的行 』,對吧 ? 不可能會在已經上排它鎖的,在上一次吧 ?
所以在上鎖前,可能就會去那張表一行一行慢慢找有沒有上鎖,但是用小腦袋想想,你覺得有可能這樣做嗎 ? 一行一行慢慢找,會找到天荒地老的。
也因為這個問題,所以就有了所謂的『 意向鎖 』機制。
它的上鎖機制如下 :
然後當要上表鎖時它的運行如下 :
接下來咱們要來簡單的談談『 死鎖 』的問題,它的定義如下 :
兩個事務或以下,因爭搶『 鎖 』資源,而產生的『 相互 』等待行為。
白話文就是,我在等你完成,你也在等我完成,結果兩個人都等到天荒地老。
~ 小知識 ~
死鎖只會出現在 RR 級別以下,如果是在 serializable 級別是不會發生的,因為它就是一個一個完成,它們要搶啥呢 ?
下述為最明顯的例子,事務 A 與 事務 B 的更新操作都在等對方釋方鎖,不過在 innodb 中碰到這種死鎖時,它會在事務 A 的更新 ( 最後更新 ) 的操作,會產生錯誤訊息,並且會進行回滾,所以嚴格來說不會一直鎖到天荒地老。
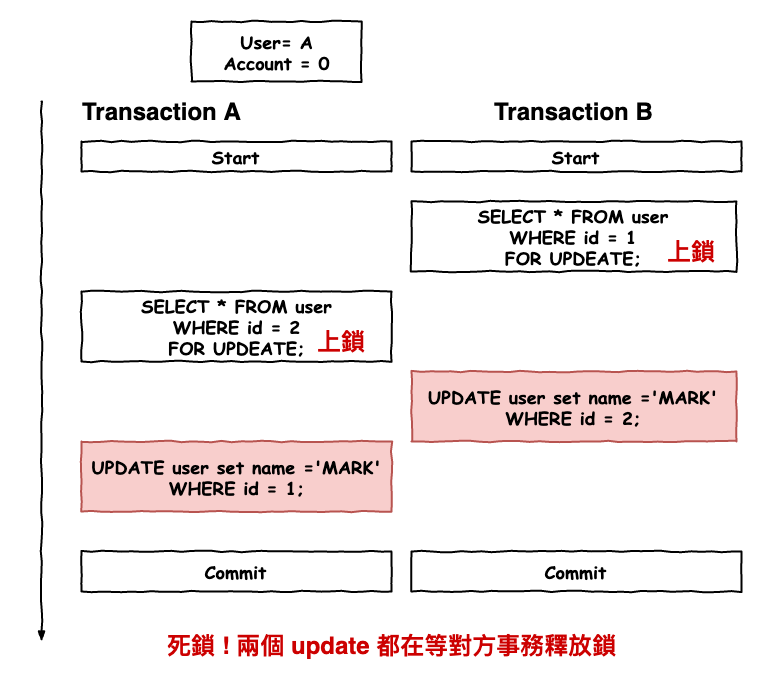
圖 3 : 死鎖範例
順到說一下,如果真的碰到這種死鎖錯誤訊息時,可以執行以下執令來看看詳細的狀況,來理解這個死鎖是如何產生的,雖然說會 rollback,但也代表這個操作是失敗了,所以還是要理解一下原因。
SHOW ENGINE INNODB STATUS
本篇文章學習了不少會讓人頭昏的東西,咱們來總結一下。
基本上有提供以下幾個級別,由上往下,從輕到重,越重的隔離級別性能越差,但相對的一致性問題越少。
這裡基本上還是請拉到上面看,然後這裡的學習重點就是,你要很清楚的知道,不同的操作指令,在 RR 實際上它是上了什麼鎖,懂了這些基本上就很夠了,因此這樣基本上你就有很高的機率可以避開一直等待鎖所浪費的時間。
這裡簡單的學習一些可能會碰到死鎖的場景,但大部份的情況碰到都會 rollback,但實嚴謹一點還是要去查查死鎖原因是什麼。
最後一致性的難題在這個章節就差不多結束了,而到了這裡事實上咱們就全部理解了 mysql innodb 它是如何實現事務的 ACID。
而本章節與上章節所介紹的併發一致性問題與解法,ACID 中的實現 :
而包含在 30-15 的文章所提到固障問題的兩個事務特性 :
這三個完成,才能符合 ACID 的最後一個特性 :
所以事實上咱們可以說 ACID 四個特性關係如下 :
一致性 = 原子性 + 持久性 + 隔離性
要完成後面三個,才能說這個事務有一致性的特性。
30-15 之資料庫層的難題 - 單機『 故障 』一致性難題
30-16 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 1 )
30-17 之資料庫層的難題 - 單機『 並行 』一致性難題 ( 2 ) ( 本篇文章 )
從以上三篇文章探討一致性的難題文章,事實上已經可以理解,併發事實上是非常複雜與難處理的事情,它所產生的資料不一致性的情境非常多種,而如果這個情境又提升到分散式系統或資料庫上的話,其難度真的非常高非常高。
這裡良心的建議 :
真的不要有事沒事為了『 性能 』而『 分散式 』,單機併發不一致性的情境都搞不清楚的情況,升到分散式資料庫會死的很慘,如果還沒死,那也有可能是因為你性能事實上根本不需要到『 分散式 』。


 iThome鐵人賽
iThome鐵人賽